When I was at school, our teachers always says to make use of the time you have. A few years later, I really realize what that means, and more importantly, why did the teacher said so. Everyone knows that you can’t turn back time, and you can’t undo things, thats obvious. Whats not obvious is that the school teachers said so, because they made some choices in the past that they wish to undo. They want to go back to being a student, but they can’t. Everyone, as they grow older, they find themselves thinking the same thing.
I used to think that the really scary thing about time is not that you can’t go back in time. It’s that you can’t slow it down or speed it up. It runs at exactly the same rate all the time. When you are having a bad time, you can’t speed it up. When you are having a good time, you can’t slow it down. Its a myth that time slows down as you get older. No, it feels like it slows down when you think about the past. It feels faster as you get older because you remember less. You remember less partly because your brain slows down, partly because things are no longer interesting, because you’ve seen such and such before, so your mind ignore it. But at the moment, when you are not trying to recall the past, in the moment, time moves at exactly the same rate as it has always been.
That said, its inevitable that people will accumulate bad experience and memories that they wish never happen. Its never about time, its about choices and implications.
This night, as I try to sleep, I found a tweet complaining that a minister in Malaysia is trying to reduce the minimum income from RM 1500 to RM 1200, citing that is to incentive employer to employ locals instead of foreign cheaper worker. There are many problematic factors here, which basically translate to, increasing or reducing the minimum income may not change anything to locals. It just shows that the politician are not very clever. Why even bother? It’ll just ruin your reputation.
To be clear I’m in no position to empathise on the fate of locals. I’m a programmer, unlikely to have much problem finding jobs. For now at least. But this is my blog, so I’m gonna write anything I want.
Nothing is free
One thing is for certain, nothing is free. Whatever you buy, your phone, your internet, your house, someone will need to make them. Everything have cost, and nothing is free. Lots of Malaysian seems to think that the government create money out of thin air. Well, the central bank does that, sure, but economic power does not come out of thin air. There is a saying that, if the government increase the salary of public worker, then the price of items will increase. We call that inflation, which surprisingly in Malaysia, can be affected by the public sector’s salary.
I like to think about it like this. There are two ways to get money, by creating tangible value, or by leverage, which I like to think of as “moving value around”. Leverage usually exist for security reason, it protect something or someone, or it exist simply because people have yet to find a way around it. Example of getting money by creating value is farming. You work, you get food, something tangible. Example of leverage is opening a shop that sell someone else’s farm product.
Of course, the shop produces some value, it advertise and distribute the farm product. But if you know where to get your farm product, and there is no cost in distributing the food, it would be cheaper for you to buy directly from the farmer. For you, the value is the food, not the shop. The shop is an inefficiency.
Now imagine, if you have one farmer and ten shop. Will there be enough food to go around? That in essence, is the problem. If there are more people that get money by leverage, there are more inefficiency in the system, the economic value is spread thin across too many people, many which do not bring value to the community.
Example, dropshipping. The only real value is marketing. The distribution is handled by some transport company, the product is made by another company, the website is created by another company. What do the dropshipper provide? If the end customer know where to get the source of the product they could get it cheaper. We say that the end customer could get better value.
Another example, someone buying up properties to rent. What are the values? I don’t know, risk of getting bankrupt I suppose, and some flexibility. What about providing a living space? No, the real estate developer provide that. If you could pay the real estate developer directly, not only do you have a living space, but you would own the house, at least part of it. What do the renter bring to the table, a little bit of security and a lot of inefficiency. Worst, you don’t have a choice, you must live somewhere. This is one of those things where no one really have a good way around it so far.
Leverage is bad
An entity with a lot of leverage is inherently more inefficient. A company with a lot of middle manager that provides little value have to support more people. Such company can get outcompeted by another leaner company that produce the same amount of value with less people, hence, less cost.
In theory, competition would drive cost down. A company that produce more value, would outcompete another company that produce less value. Unless, the more inefficient company have leverage. This is bad for the customer as in the end, the customer would receive less value for the product.
Government offices are great example of this, as government have no competition (locally at least). In fact, any government linked employment, or near employment have this issue. Think about having your IC copied at a JPJ office. What are their value? What are their leverage? Yet, they charge RM 1 a pop. The fact that they are doing side business clearly shows that there are not enough tangible values being spread around there. Too much leverage.
National automotive company are another great example of leverage at play. They have large amount of internal rebates and less import tax that their cost is lower compared to companies outside the country. However, for the same amount of cost, company outside of the country can produce much better product. The end value to the customer is lower. You are essentially paying twice the normal price for your car.
Leverage is good-ish
However, national automotive company also provide more economic values to the country as the money they receive goes back to the community, probably. Which is a very good point, and a good use of leverage, the protect something, the economy of the country. But here is the thing, if the local company need more people to produce the same amount of value, the local company is not a very good company. It is inefficient. Probably poorly managed. What if outside company, which are better managed, produce the product locally instead?
Here is the thing. Well run companies are methodological, precise and have good, probably quantifiable reason to do things. If they are not such, they are not very good company. The very reason they don’t produce the product locally, is because they could produce more value, outside the country. If they produce the product locally, they may need more people to produce the same amount of value. Increasing the cost of people will bring even quantifiably less reason for the good company to produce product locally. It’s nothing personal, it’s just cold calculated business.
To make matter worst, with little reason to improve, as they are protected by the government, local company can sit comfortably not producing much. That is why you are stuck with either, poor product from local company, or expensive good product from other country.
Nothing is free
In the end, within the isolated community, the people within the community themselves must produce value. Nothing is free. You either work hard, or work smarter. You plant more food, or use machines to plant more food. But a large proportion of the community must produce value.
This is also, the reason why ideas such as universal basic income is unlikely to happen in Malaysia. The value must come from somewhere, with enough quantity as to meet the “basic income”.
Education does, produce value out of thin air. However, it is pointless in my opinion to focus on having people studying hard, going to universities. Only some people are suitable or even capable of studying to that level. In the end, without enough economic power in the country, they are better off going outside the country anyway. Any values they produce will be spread out across many people anyway.
Worst, higher education are value multiplier. They produce farming machines, but there must be farmers to use those machines in the first place. People must create value in the first place, in order to have those values multiplied.
RM 1500 is nothing nowadays. The lower bound, in terms of producing value is too low in Malaysia. The focus should now be on those that do not go to University, do not go to boarding school, future Mat Rempit. Heck, there should be less university. If you are targeting everyone to have university level education, you might as well make all school have university level-ish education. Don’t give people fishing pole, teach them how to farm fish.
Just remember, you felt it before, and before, you feel like you will feel down forever. But between then and now, there are moment that you feel happy. So even if you feel like you will feel down forever, you’ll probably feel happy again, just like the last time you feel down.
First of all, it is ridiculously hard. If you think it’s not hard, you either, missed some variables, or ridiculously lucky. The more accurate my simulation gets, the harder it is to find a good strategy. A strategy that works before, may not works now.
Stocks prices are very hard to predict. Finding good company is not very hard. Finding good company at a good price is. The better the company perform, the more people buys it, and therefore the more expensive it gets. The reverse may also be true, but at if a company is performing poorly, it may get even poorer or worst, get delisted, so even if the stock is cheap, its not necessarily a good buy.
Lots of people says that we should look at the intrinsic value of a company to know the fair price. The problem is, what is its intrinsic value? Is it the value if the company is liquidated, or “book value” as it was called? Consider this thought experiment: A company that have a book value of 1 billion USD. However, it does not have any dividend, and it is guaranteed that it wont have any dividend, and it will never initiate stock buyback forever. It is run well enough that it will never go bankrupt or shrink in business, let say in terms of income, but not well enough that it will never grow. What would be the marketcap for this company? Considering that it will never have any dividend, what is the upside to the stockholder? Considering that it will never grow and will never initiate any stock buyback? Why would this company’s stock price go higher? If you know that price would never go up, why would you buy it? Considering no one will buy it, everyone would want to sell it, and therefore the price would fall. But if the underlying company will never go bankrupt and will always remain the same, why would the price go lower? You can say that it is a good hedge, but why choose this over bond which will yield a tiny, but some return? This company is, in some essence, what bitcoin is in terms of intrinsic value.
So, we have establish something. Dividend is an easy… intrinsic value of a company (assuming the company will never get delisted and run well enough). A second factor is harder. A stock’s business must grow. But why must it grow you may ask? Well, if the business grew, the stock price would also grow. That however, is where the complication comes. A stock price is determined by the market. The market is also, trying to make money, and therefore, try to predict the intrinsic value of a stock in the future. Let say the market assume that the sales of the company is the measure of the fitness of the business and therefore it’s instrinsic value, and the price follows the business’s intrinsic value. The market would then want a business that will increase in intrinsic value, as it assume that the price will increase. However, the act of buying the business increase the price of the business, possibly above it’s current intrinsic value. The market would keep buying the business, as long as it’s current price is lower than the future expected intrinsic value. If the current price is the same as the future expected intrinsic value, and the future price of the stock matches the future expected intrinsic value, would the price of the stock increase anymore? If not, why would the market buy the business? If it will, and the market does buy the business, the price of the stock would increase and therefore why would the price of the stock increase?
The back and forth create a balancing act which means, a company’s marketcap usually does not match a company’s intrinsic value. It’s usually match what the expected future intrinsic value of the stock. This causes another question. How far in the future?
Here comes another complication. The future can change, a lot. The further the future, the more chance it can change. Additionally, money now, is more valuable than money in the future. Therefore, the future intrinsic value must be higher than some percentage of current price. Because the future is unknown, there is a chance than the company’s future intrinsic value does not match the expected intrinsic value to break even. Therefore, there is only a certain amount of futureness that the market would be willing to predict. The more stable a company is, the more forward looking the intrinsic value is. However, it also means that the current price of the business will get higher.
This is without considering the fact that some of the market, would also try to predict the future price of the business, instead of just the future intrinsic value. As the future price of the business is likely the predicted future intrinsic value of the business, when predicted in the future, this price of the market would still buy the business, in hope to out-predict those who only predict the intrinsic value, leading to a very high valuation.
Oh my brain, please stop thinking. I need to sleep. Lets think about whatever we want to do tomorrow. No no…. we don’t need to write a blog post. We need sleep.
Do you get me? Let me sleep please…. We will ponder on our life choices tomorrow.
Time goes on whether we like it or not. Time does not slow down or get faster. As we think about time, time moves on. There is nothing we can do about it.
Ah here we go again…
Time is life. Time wasted, is life wasted. Life wasted, opportunity wasted. So much opportunity wasted. Yet, so little time. Wasted opportunity imply the existences of it. At the same time, there is only so much that we can do.
Its not about the opportunity that we choose, it’s about the opportunity that we don’t. But choosing something, imply something else that is not choosen. In another word, there is always opportunity not taken, because we took some other opportunity.
There are life not taken, because we choose another life. Is one better that the other? No one really knows. When people are asked about what do they regret, its usually about things they don’t do. At the same time, they probably don’t do it, because they choose to do other things. If they do choose it instead, would they regret not doing the other thing?
Here in Malaysia, we have 65% excise tax on cars. If you pay RM 500 a month for your car, about RM 200 of it goes straight to the government. Not to Proton not to Perodua or Toyota. Some say that does no apply to local manufacturer, but I’ve yet to find concrete evidence that they are exempted from it.
I’m 26 years old that have no car. Its not that I can’t afford them, I just really hate loan. But its way past due that I take the bullet and accept this constantly depreciating item in my life. Which brings me to my question, new or used car.
First, some background, I’m single, I go to work with a motorcycle. I will most likely not going to use the car to go to work in order to prevent more of my money flowing to the government. So fuel consumption is not an issue. Its most likely going to be used to balik-kampung to Kedah. Once every two months perhaps. Car must have ABS. I had a scare before somewhere near Slim River where the Axia I used got a case of locking brakes. Car must be practical, really, the main purpose of the car is to carry stuff that I can’t carry with my motorcycle box. I have like a big table, that preferably can fit into the car. Folding rear seat is a must. MPV is even nicer. Car must be reliable or do not depreciate much. This means its mileage should not be too high. Or, its so cheap that it can’t go even lower. Car should be locally made (not necessarily designed), because its easy to find parts or repair. This leaves us to Proton or Perodua.
Preferably, I don’t want to have a loan at all. I have some money, but not enough to buy a new car. I thought of getting a dirt cheap Proton Saga to save money. But those generally don’t have ABS. More importantly, the old saga cannot fold down the rear seat, a puzzling design choice. A Viva does not even have ABS option. This leave a Myvi, but I really like the 2011 “lagi best” model, which is still expensive. To my surprise, I might as well get a new one, which is only about 50% more expensive on most case. I thought, cars depreciate really fast, but this is a 8 year old model. Why does it still cost this much? I’ve looked at carlist.my, mudah.my, facebook, all more or less the same. Which makes me think, is this the norm? How much do car really depreciate in value?
Looking into it….
Using my programming skills, I’ve scraped a website that list car for sale in Malaysia, which will be kept unnamed, for legal reason. Unlike mudah.my, this site make sure that they don’t list deposit price, or sambung-bayar price, only sale price, although generally its not OTR. This make it easy to scrape, no need to clean data. I only scrape Proton and Perodua models, remove those whose mileage is more than 250 000 km, and only consider automatic transmission. Also, they can’t be more than 15 years old, and I excluded listing from ‘dealer’, as I simply don’t trust them. Majority of the seller here are agent or private seller. And because I don’t want a really old model, I’ve specified the model name explicitly.
So what kind of population are we looking at here. For giggles, I’ve disabled dealer filter for this occasion:
Hmm, what brand is sold by who?
Fascinating! It seems that although in total, while there are more Protons listed, they are generally sold by dealers. Hmm…. Anyway, lets ignore that because we are not considering dealers. Then the most listed car is without much surprise, the most popular car in Malaysia, Myvi. Most listed by private seller and most listed by agent. The next privately listed car is Proton Saga. Surprisingly the second listed car by agent is actually Alza, not Saga.
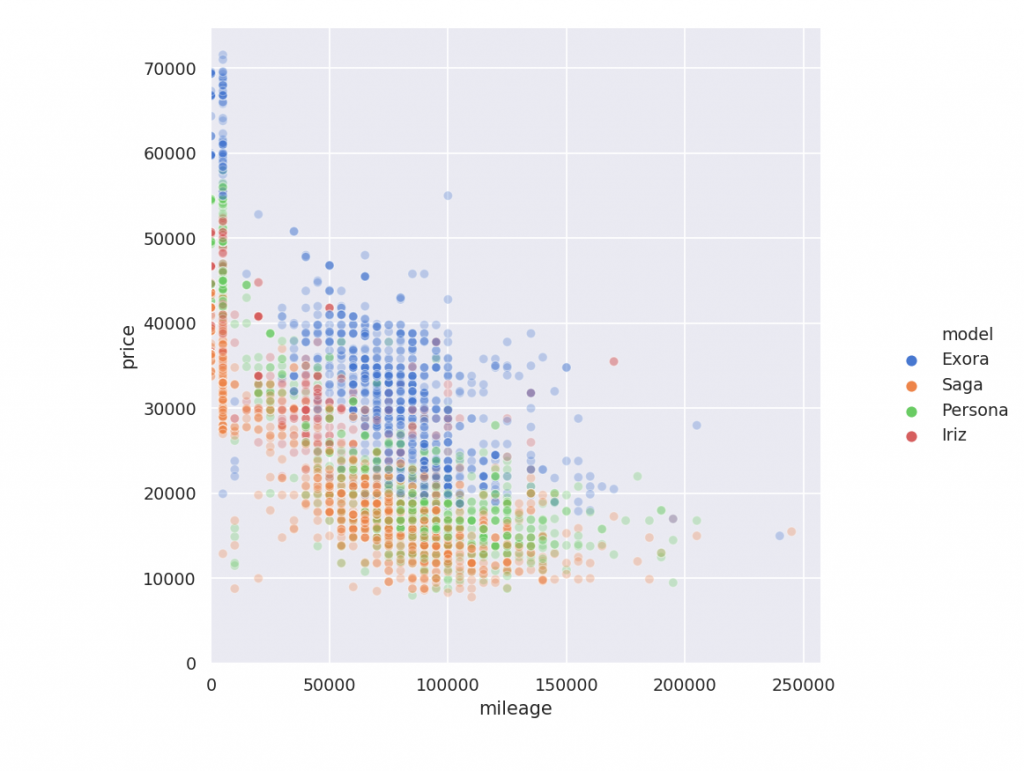
Side note, I actually really want an Alza. But their price does not go down in the used market, not much at least. Now, let us plot their listed price over their mileage. This should show us how much value a car lose over the distance it traveled. I’ve splitted the scatter graph between Proton and Perodua, as 17000 points in a single plot is very hard to decipher.
Price over Mileage
PeroduaProtonBoth
Simply said, there is no easy correlation between mileage and price. We do have some pattern however, after 100000 km, the price does not drop much anymore. Depending on car, 60000 – 80000 km is a good target to look far.
There is a strange anomaly at 10000 km, where there is a bunch of cheaper car. I suspect this is some bad data, some seller putting refurbished car or just saying car with less than 50000 km as 10000 km.
There are other patterns also. Viva pretty much don’t change in price. It is cheap in the first place, and does not go much cheaper. For some reason, Iriz increase in price as mileage grow? From the scatter plot, there aren’t many car being sold when their mileage is lower than 40000 km. I suspect the sellers just say they are 10000 km in mileage.
From the scatter plot, there aren’t many car being sold when their mileage is lower than 40000 km. I suspect the sellers just say they are 10000 km in mileage. That said, mileage just does not affect the car price much and it highly vary from seller to seller. Really, what you want to look at (at least what sellers are looking at) is the age of the car.
Price over Age
PeroduaProtonAll
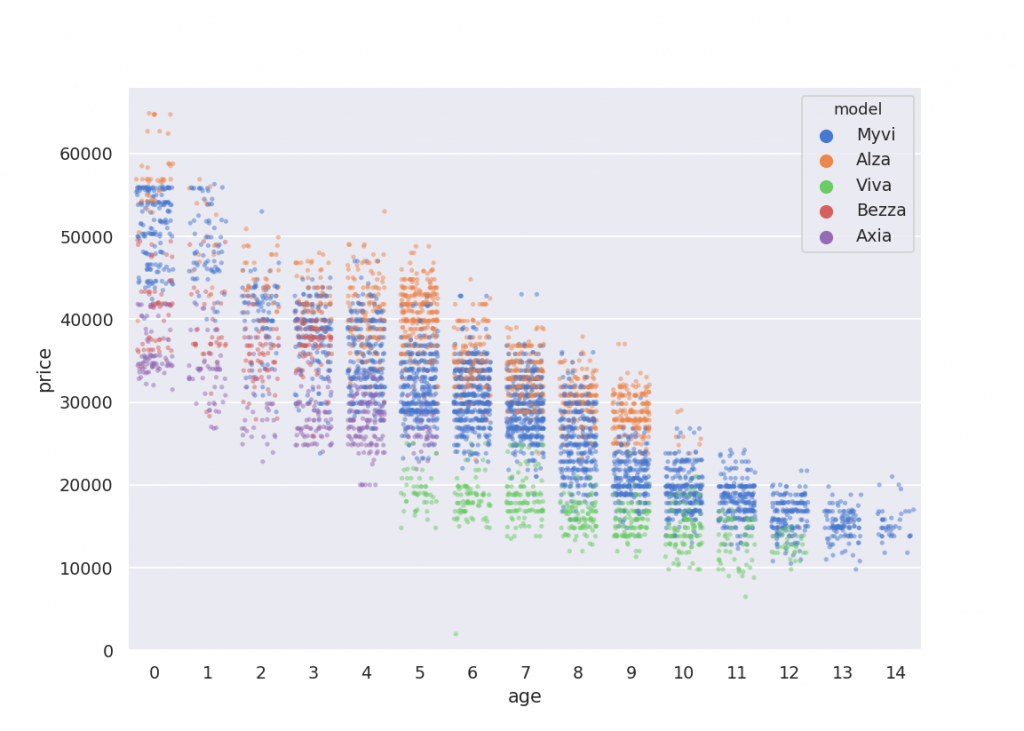
Now we are looking at something. The price of a car is somewhat proportional to its age. There is a lower bound however. No car is priced below RM 10000. Brand-by-brand, Perodua does command a higher price that Proton. In fact, Alza is consistently more expensive than an Exora at age 2+. At 4+ year old Axia is actually more expensive that a similarly aged Saga. At 7 year old Saga and Persona have identical price, AND priced more or less the same as a Viva? In fact, at 8 year old, an Exora is priced similarly to a Myvi.
That said, Persona wise, this is the old persona, not the new one. Iriz still goes up in price a bit. Bezza also have a bit of a price hike at age 3. Is a newly released model more expensive when it first lunch? A new version does bump up the price a bit. For example, 7 year old Myvi is significantly more expensive than an 8 year old Myvi, due to the 2nd gen model. Axia is significantly more expensive than Viva no matter how you look at it.
A few things to keep in mind, these are all listed price. It is most likely not OTR price. Add 3k to 5k for that. It is possible that the buyer can haggle for the price, which lowers them, but I’m no good at that. Simply said, the actual buying price could be higher for me.
The price depreciation does slow down a bit. There seems to be a ulower bound of RM 10000, or RM 20000 for MPV where their price will not go lower. Or maybe the model is just not old enough for the price to go lower.
It seems that a good estimate of how a price of a car drop is to say that it have a half life depending on the model. Meaning the price will halve over some period of time. That said, its not like 2 or 3 years. Perodua seems to have a half life of 6 or 7 years. Saga and Persona have a half life of 4 to 5 years.
Much of this is perhaps just market sentiment. Perhaps. I know I don’t want a second hand Persona, because I’ve used one. It had a broken fuel gauge, then the immobilizer immobilize it, something wrong with the computer, completely replaced the dashboard, still broken fuel gauge. But that is the old Persona. Iriz have a favorable review, and the new Persona is based of Iriz. Saga is so simple, not much can go wrong. Exora on the other hand, have a turbo. And a bunch of canggih stuff. See how the price drops.
Conclusion
If you wanna buy a second hand car, buy a Proton. If you wanna buy a new car, Perodua is a better choice. Me? Old saga cannot fold rear seat down. New saga are 25k+, listed price, not OTR. OTR is probably 30k. I might as well buy a new one at 35k.
Myvi is a better choice. Lots of people selling them. A ‘lagi best’ EZi model of mileage less than 80000 can be found for 22k, which OTR is probably 25k. And its rear seat can be folded down FLAT. However, it does not really have a bonnet, which means cargo length is limited. Bezza is too new, and its rear seat is vertical. Alza however, not only have a flat folding rear seat, it have TWO rows of flat folding seat! Making it a van, which is awesome! But, I can’t find a good one below 30k, list price… When a new one is 55k, its hard to justify buying a 9 year old car for slightly more than half price.
So, did I make a decision? Nope. Why? Simply said… I’m cheap.
I’m quite conservative about how my application store its data. I prefer SQL over NoSQL. I prefer it’s security of the dynamic of NoSQL, which you would eventually probably use an ORM which have schema anyway. Relational databases have been used for decades, so it must work right? And really, most of us will probably never going to need the performance of a NoSQL database. That said, there are good uses for things like Redis, or other form of Key-Value store, notably for simple stuff like configurations. But for real work, for me SQL is the right way to go.
But what if you don’t know the structure of the data of the application? What if there are no structure? What if there are indeed patterns, but there are many special cases where in the end, the structure does not matter much.
For those who are not technically familiar with relational database, in relational database, there are things called ‘Table’ and that is where we store data. For example, if I have many car, I will put create a ‘Car’ table, and in the car table, I will declare the car’s properties such as the height and weight. But all car must have the same attribute. Sometimes, if some car don’t have a certain attribute, we just don’t fill the attribute for that car. That works. Sometimes, instead of cars, we have to represent vehicles, some can be car some can be bicycle. And there are many ways to represent this data, but the gist of it is this, all things of the same type generally have the same properties.
But what if out of a hundred car, two car have a special properties which no other car have. This is what I call special cases and I hate special cases. It makes the code ‘unclean’ and kinda makes me ‘itchy’. Sometimes, these two car have special calculation that need special treatment. Generally we put the name of the car in the configuration file and then special-handle them when they occur somewhere in our code.
In my latest project, I have a bunch of these special cases where this data is the same as these data, or these data is equal to these data multiplied by 100. But only these particular data. In this case, the number of ‘car’ is fixed and there are predefined number of them. But some of it have special characteristic which is not the same as other stuff. On thing the got in common is that they represent values over time. Or in another word, I was to keep record of what are the weight of this care at this particular time. And some car does not have weight.
The reason for this is that previously the business flow of the company is to use Excel sheet with various formula. And some cell is this cell multiplied by these cell. Using Excel is fine by itself, the problem is, half of the time, there are no obvious pattern to derive from. It is very hard to design the sql table for this case.
The original code of the project uses a key-value system where each value is mapped to a key. There can be multiple value per key which also have timestamp of when that value is active. And then in clientside there are list of formula of how to calculate certain values which is calculated from other values. Previously these ‘formula’ pattern is used in two place. In a place where the used periodically key in values, and a background process where it will fetch data from another service, and transform them using these formula. There are also other background process which run some calculation on these values to get some other values such as average, but those are hardcoded.
At first, I modified the key-value formula system so that the formula is stored in the database. Then it is calculated on clientside when needed as most of the calculation is for view purpose. Then came the graph, and some of the graph’s value is calculated from other value. That means if I were to calculate it on clientside, the browser would probably hang, and calculating it on demand would take too much time. So, I make a background task, kinda to calculate these value to store then for graphic purpose. And then some of the value require average of other values, which mean it needs access to multiple values over multiple time. And then I make it work. I make sure to sort the calculation order topologically for correctness, in case a calculation depends on another key which is also calculated. I make it as fast as I could by caching the data used by calculation before sending it to database, which significantly improve its calculation speed as it does not have to hit the database. I make the formula work while having partial set of data, without hitting the database at all, allowing the clientside to ask the server to quickly calculate the resulting value which allow the user to see the changes before it is saved.
Managing this large number of keys is a huge hassle, so I make a template system for the configurations so that I don’t have to repeat repeated patterns. To save space, value segment next to each other that have the same value is combined, effectively compressing the database. When the formula of a value is the key of another value, basically it just link to the other value, and storing the duplicated value is a waste of space and compute resource. So the storage layer is modified a bit so that it just point to the actual value. Linking is a great feature as it allows us to define mapping for a page and then link them to actual data later one. Which is really important as the data may came from multiple other page arbitrarily.
In another word I’ve made it in a way that any time-series number data can be relatively easily represented and linked to each other. Now here comes the big question, Why should I use it? Everyday I ask myself this question, and everyday it always comes to “How else to do this?”. You see, when you made such complex things you kinda ‘own it’. And you want everything to use it. Much like when I made a monadic LoadableResource pattern. But is it really needed? A question I ask myself everyday. My co-worker said that other developers don’t understand it. But ‘other developers’ is the kind of developer which needs to be explained the different between an array of string and an array of dictionary. What does they understand?
Some of the page now does have some pattern. But to me that sounds like it will need to create two more additional table, making sure the query is correct and making sure the calculation is correct. No to mention some data comes from other page. And the structure of the other page may not be the same. The list of car on the other page is not the same as the list of car in this page. And how are you going to map from one page to another? By creating a configuration file. I know, lets make sure all configuration file is stored in the same place and for mapping between two page, have the same structure. That sounds a lot like the whole value mapping system before, except there will be multiple places that do the same thing.
For me the biggest downside is managing the mapping names. There area a lot of them. Up to 6000 right now. But they are defined in multiple file, each file separated by its domain. And there are the template system. Its just that no one is using them except me. Even so, it still feels a bit cumbersome for me. If it gets even more complex, it might as well be its own programming language. Additionally, if it makes so much sense, why haven’t I heard about such pattern before? Is it just very domain specific, or I am just missing the term to google it? Who knows.
So I finally quit. It was an okay quit, I guess. A but abrupt, yes, I admit. But it had to be done. And right now, I’m jobless and I probably got enough money to survive until the end of next month.
The thing is, it turns out, finding a job is hard work. Finding a suitable job, that it. I tried ServiceRocket, did not even get an interview. I registered to a hiring firm, got an interview to a small local company. Did not pass. Apparently I’m “not ready yet technically”. “not ready yet”, I would agree, “technically”… I’m not exactly sure. But I couldn’t say that is wrong either. I don’t really have much to say on things that matter.
If I learn anything on my strange internship, its that technology does not matter. What matter is what effect do the technology bring to the table… the meeting table… with the client in front of you. Sadly my previous job do not offer much in that sense. Something that I’m paying right now.
But hey, I got to start somewhere right? Which is also not that easy for me. In my CV I have nearly 4 years of experience. But without much impact, those experience are poor experience. Starting somewhere, would mean entry level, and how am I going to get an entry level job with 4 years in my resume? The interviewer would be like “Are you hiding something?”, which I kinda am. Those are remote jobs, they are not very…. impactful.
Anyway, after that interview I tuned up my resume as high as I can. It feels a lot more impressive now. Anytime I feel down, I look at it, and it makes me feels a tiny bit better. I gone through my backup from the year 2014 and see what I did with Coglab.biz. Put everything that I think ‘impactful’ in my CV. It feels a bit too ‘low-level’, but I don’t have much ‘high-level’ thing to be proud about. Hopefully that is enough. I sent it to several bigger companies today. But today is Saturday, they’ll probably process those on Monday, which brings me to the next agenda… Convocation.
Ahhhh great. I’m going to meet old friends and when they ask what am I up to right now, I’m going to have to say “Unemployed”. And then they’ll say “Seriously?” And them I’m going to say “Yup!”. And then a series of uncomfortable conversation. My Convocation is this Monday by the way. Which also brings other complications to my resume. I hate this. Its like my birthday and my friends wedding. It only reminds me of what I did not do, and its too late to do it.
As the job hunting continues, I have several leads right now. The resumes I sent to those companies, may take more than one week to process. Abidzar said that he have some friends that want to make a new team, a not-web-development team, and I could join it if I could hold on until next month or so. And he sent my resume for a contract job with Petronas, and another C++ job, I dont really know where. I got an interview from a recruiter for a job in Japan. Its a bit too far, but if I did not take this up, I’ll regret myself. There was another recruiter from Singapore. I turn that one down before, because I don’t want a job outside KL, well at that time at least. I turn down many recruiters before. Man, they can be quite handy now.
I’m bored. I wanna quit my job and work on something else.
The guy at one of the talk I’ve been said to the audience, “What do you wanna do?”
I honestly have no idea. Today I got an email to an invitation to Asia’s Rice Bowl awards. As an audience, not a participant. I don’t know how did I get the invitation. Zu did not get it. Abi Dzar did not get it. I know I won’t go there. I got nothing to show for it. If there is anything I learn from Superb and Symbiosis, among these guys, I’m no one.
Heck, who am I? Some might say a really good coder. But in these few week, one thing I’ve learn is that, even in that aspect, I’m not really that good. I just have an early head start. And if I stay and my current job, I’m gonna be left behind. It really is quite sad. Without my skill, who am I?
I could not even do ImbasPay well. Not even Bahasapp. I could make excuses here and there, but the fact is, I really don’t know how to manage a project. Need to go and work somewhere else.
Thinking about Superb and Symbiosis, I really have a talent of getting myself into places where I probably should not go. Likely due to my presentation skill. A quirks I get back from secondary school. You see, sometimes when I do some public speaking, it can work really well, and people for some reason have the impression that I could be a champion or something. Unfortunately I have a very poor social skill which makes me awkward as hell. And in business, leadership and I guess life, social skill rules. If I could code my way through it, I would. I’m kinda am.
Oh well, what am I blabbering about again? Yea, changing job. The thing is, I need to complete ImbasPay and then the IIUM research thing and then I can safely change job. Which is a lot of work. Sometimes I ask myself, do I regret making choices that lead me to today. Well, then I respond, “If I keep thinking of these regret, I won’t be able to move”. So many regret. But it does not mean much today. I really need to learn how to say “No”.
Something amazing happened in the past few days. I actually have some spare time. And in those spare time, I’ve manage to update the IIUM Schedule suite of tools with some fixes. For Automatic IIUM Schedule Formatter, the changes are mostly internal and therefore the changes are not so visible. Actually I made the changes several month ago, but for most people, nothing changed.
The SemiAutomatic IIUM Schedule Maker one the other hand, have one fix and its an important one. Previously the way it scrape IIUM’s schedule data, it assume that for each section, there is only one row. I made it that way because I thought all section is like that. Later on it become apparent that some section data are contained on more than one row. So it originally will only consider the first row.
In another word, previously a significant majority of user did not see the whole section’s schedule. And now it has been fixed. I planned to do a bigger update regarding things like navigation, but it seems that the prereg date is very near. So I just do the fix and declare it V7. Another useful update is now it can consider tutorial classes. It can now prompt you if a tutorial class clash with another section.
That is all regarding IIUM Schedule. On an unrelated matter, for those of you who are interested in programming competition, specifically ACM ICPC, or want to know more about it, I’ve made a post on another site that introduce you to the world of competitive programming. So please check it out and tell your friends about it. That is all for now. Thank you for reading.